

This is an agile DuckDB extension that provides Java-based connectivity with network access and multiprocess support.
Based on the description, this extension can do following:
-
Enables remote access to DuckDB via TCP/IP from network, instead of local connect only restriction.
-
Supports multiprocess access to DuckDB instead of single-process restriction.
-
Provides PostgreSQL wire protocol compatibility (JDBC, ODBC, etc.), allowing DuckDB to serve as a PostgreSQL database.
-
Offers a dedicated access client, which has:
-
Advanced features
-
Comprehensive data dictionary access support
-
-
You can use COPY syntax to import data with high performence, this compatible with PG CopyManager.
-
Provides self-managed data services and API.
-
You have multiple ways to connect to this extension:
-
Directly connect to the server with jdbc, odbc, …
-
Connect through a connection gateway which multiple servers(can on different host or different process) are behinds it.
-
Embed the compiled jar package into your own application.
-
Register a data service and access data through REST API.
-
# make sure you have JDK17 and maven 3.6+ ready.
# Download source code
git clone ...
# compile it
cd slackerdb
mvn clean compile package
# All compiled results will be placed in the dist directory.
# compiled Jar packages,
# default configuration files.
# Database name, default is none. data= # Path where data files are saved # ":memory:" indicates in-memory mode (data will be lost after restart) data_dir=:memory: # Temporary files directory during operations # Disk mode: Defaults to data_dir if not specified # Memory mode: Defaults to system temp directory if not specified # Recommended: Use high-performance storage for temp_dir temp_dir= # Directory for extension plugins # Default: $HOME/.duckdb/extensions extension_dir= # Run as background daemon (true/false) daemon= # PID file location # - Locks exclusively during server operation # - Startup aborts if file is locked by another process # - No file created if not configured, and no lock. pid= # Log output destinations (comma-separated) # "CONSOLE" for stdout, file paths for file logging log=CONSOLE,logs/slackerdb.log # Log verbosity level log_level=INFO # Main service port # 0 = random port assignment # -1 = disable network interface # Default: 0 (disabled) port= # Data service API port # 0 = random port assignment # -1 = disable interface (default) port_x= # Network binding address bind=0.0.0.0 # Client connection idle timeout (seconds) client_timeout=600 # External remote listener registry endpoint # Format: IP:PORT # Default: none (disabled) remote_listener= # Database opening mode. # Default: READ_WRITE access_mode=READ_WRITE # Maximum concurrent connections # Default: 256 max_connections= # Maximum worker threads # Default: CPU core count max_workers= # Database engine threads # Default: 50% of CPU cores # Recommendation: 5-10GB RAM per thread threads= # Memory usage limit (K/M/G suffix) # Default: 60% of available memory # -1 = unlimited (memory mode only) memory_limit= # Database template file template= # Initialization script(s) # Executes only on first launch # Accepts: .sql file or directory init_script= # Startup script(s) # Executes on every launch # Accepts: .sql file or directory startup_script= # System locale # Default: OS setting locale= # SQL command history # ON = enable tracking # OFF = disable (default) sql_history=OFF # Minimum idle connections in pool connection_pool_minimum_idle=3 # Maximum idle connections in pool connection_pool_maximum_idle=10 # Connection lifetime (milliseconds) connection_pool_maximum_lifecycle_time=900000 # Query result cache configuration (in bytes) # - Only caches API request results (JDBC queries unaffected) # - Default: 1GB (1073741824 bytes) # - Set to 0 to disable caching query_result_cache_size= # Data service schema initialization # - Accepts: # * JSON file path (single schema) # * Directory path (loads all *.service files) # - Schema files should contain service definitions in JSON format data_service_schema=
# PID file location # - Locks exclusively during server operation # - Startup aborts if file is locked by another process # - No file created if not configured, and no lock. pid= # Log output destinations (comma-separated) # "CONSOLE" for stdout, file paths for file logging log=CONSOLE,logs/slackerdb-proxy.log # Log level log_level=INFO # Run as background daemon (true/false) daemon= # Main service port # 0 = random port assignment # -1 = disable network interface # Default: 0 (disabled) port=0 # Data service API port # 0 = random port assignment # -1 = disable interface (default) port_x=0 # Network binding address bind=0.0.0.0 # Client connection idle timeout (seconds) client_timeout=600 # Maximum worker threads # Default: CPU core count max_workers= # System locale # Default: OS setting locale=
Note: All parameters are optional.
You can keep only the parameters you need to modify.
For parameters that are not configured, default values will be used.
-
Data service work with port x, please make sure you have enabled it in server configuration or from command parameter. It’s important to note that we have no consider on data security. This means data services must work in a trusted environment.
User login (note: this is optional). After success, a token will be
provided.
Context operations or SQL access that requires context variables will
require token.
If your program does not involve context feature, you can ignore this
login.
Put it simplify, the token is currently used as the user ID.
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST |
Path |
|
Response example:
Success response (200)
{
"retCode": 0,
"token": “yJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9”,
"retMsg": "Login successful."
}
User logout
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST |
Path |
|
headers:
| Attribute | Value |
|---|---|
Authorization |
NzJjYjE3NmQtN2Y2ZC00OWMyLWIwODAtYTU1MDE3YzVmZDU1 |
The token information here is obtained when call /login in earlier
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
}
set context
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST |
Path |
|
headers:
| Attribute | Value |
|---|---|
Authorization |
NzJjYjE3NmQtN2Y2ZC00OWMyLWIwODAtYTU1MDE3YzVmZDU1 |
The token information here is obtained when call /login in earlier
request body:
| Attribute | Value |
|---|---|
key1 |
value1 |
key2 |
value2 |
… |
… |
keyx |
valuex |
You can set one or more key-value pairs at once, or you can set multiple key-value pairs by calling setContext multiple times.
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
}
remove context
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST |
Path |
|
headers:
| Attribute | Value |
|---|---|
Authorization |
NzJjYjE3NmQtN2Y2ZC00OWMyLWIwODAtYTU1MDE3YzVmZDU1 |
The token information here is obtained when call /login in earlier
request body:
| Attribute | Value |
|---|---|
removedKeyList |
[key1,key2, ….] |
You can remove one or more key-value pairs at once, or you can remove multiple key-value pairs by calling removeContext multiple times.
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
}
register a service
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST |
Path |
|
request body:
| Attribute | Value |
|---|---|
serviceName |
service name |
serviceVersion |
service version |
serviceType |
service type, GET/POST |
searchPath |
sql default search path, Optional parameter |
sql |
SQL statement, can contain such ${var1} variable information |
description |
description |
snapshotLimit |
how long the query result will be cached, Optional parameter |
parameter |
parameter default value when query api not provide parameter value |
snapshotLimit format: 3 hours / 30 minutes / 45 seconds
Request example:
{
"serviceName": "queryTest1",
"serviceVersion": "1.0",
"serviceType": "GET",
"sql", "SELECT 1"
}
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
}
unregister a service
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST |
Path |
|
request body:
| Attribute | Value |
|---|---|
serviceName |
service name |
serviceVersion |
service version |
serviceType |
service type, GET/POST |
Request example:
{
"serviceName": "queryTest1",
"serviceVersion": "1.0",
"serviceType": "GET",
}
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
}
list all service
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
GET |
Path |
|
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
"services":
{
"Query1":
{
"seviceName" : "Query1",
"serviceType" : "GET",
....
}
}
}
API query
| Attribute | Value |
|---|---|
Protocol |
HTTP |
Method |
POST or GET |
Path |
|
headers:
| Attribute | Value |
|---|---|
Authorization |
NzJjYjE3NmQtN2Y2ZC00OWMyLWIwODAtYTU1MDE3YzVmZDU1 |
snapshotLimit |
Optional. used to overwrite service definition. 0 means no result cache |
The token information here is obtained when call /login.
The token is optional, if you use context in your sql statement, you
must set it.
snapshotLimit format: 3 hours / 30 minutes / 45 seconds
GET Request example:
GET /api/1.0/queryApi?context1=xxx&context2=yyy
POST Request example:
POST /api/1.0/queryApi
{
"context1": "xxx",
"context2": "yyy",
}
Response example:
Success response (200)
{
"retCode": 0,
"retMsg": "Successful."
"description" "test 1",
"cached": false,
"timestamp": 17777700,
"data":
{
"columnNames":["col1","col2","col3"],
"columnTypes":["INTEGER","INTEGER","VARCHAR"],
"dataset":[[1,2,"中国"]]
}
}
SQL REPL Server provides an asynchronous WebSocket interface for executing SQL queries and fetching results in pages. It is useful for long-running queries where you want to avoid blocking the client, and aligns with the MCP (Model Context Protocol) philosophy of using WebSocket for bidirectional communication.
To use it, ensure the data service API port (port_x) is enabled in server configuration.
Connect to the WebSocket endpoint:
| Attribute | Value |
|---|---|
Protocol |
WebSocket (ws:// or wss://) |
Path |
|
Once connected, you can send JSON messages with the following general format:
{
"id": "unique-request-id", // used to match responses
"type": "message-type", // one of: start, exec, fetch, cancel, close
"data": { ... } // payload specific to the message type
}
The server will respond with a JSON message that mirrors the request id and includes a retCode (0 for success, non‑zero for error) and relevant data.
A session is created by sending a start message. The server returns a sessionId that must be included in subsequent messages for the same session.
Start message:
{
"id": "1",
"type": "start",
"data": {}
}
Response:
{
"id": "1",
"retCode": 0,
"retMsg": "Session created",
"sessionId": "session-123"
}
All further messages for this session must include "sessionId": "session-123" in their data field.
Submits a SQL statement for asynchronous execution. Returns a task ID that can be used to fetch results later.
Message:
{
"id": "2",
"type": "exec",
"data": {
"sessionId": "session-123",
"sql": "SELECT * FROM large_table",
"maxRows": 1000 // optional, default is 1000
}
}
Response:
{
"id": "2",
"retCode": 0,
"retMsg": "Task submitted",
"taskId": "550e8400-e29b-41d4-a716-446655440000",
"status": "running" // or "completed" if result fits in first page
}
If the SQL execution fails immediately (e.g., syntax error), the response will contain retCode != 0 and an error message.
Retrieves a page of results for a given task ID. The endpoint returns a fixed number of rows (up to maxRows specified in execute) and indicates whether more rows are available.
Message:
{
"id": "3",
"type": "fetch",
"data": {
"sessionId": "session-123",
"taskId": "550e8400-e29b-41d4-a716-446655440000",
"maxRows": 100 // optional, overrides the default page size
}
}
Response:
{
"id": "3",
"retCode": 0,
"retMsg": "Success",
"taskId": "550e8400-e29b-41d4-a716-446655440000",
"status": "completed", // "running", "completed", or "error"
"hasMore": false, // true if there are more rows to fetch
"columnNames": ["id", "name"],
"columnTypes": ["INTEGER", "VARCHAR"],
"dataset": [
[1, "Alice"],
[2, "Bob"]
]
}
If the task is still running (status = “running”), dataset may be empty and hasMore will be true.
If the task has completed and all rows have been fetched, status becomes “completed” and hasMore false.
If an error occurs during execution, status becomes “error” and retMsg contains the error details.
You can send multiple fetch messages until hasMore becomes false. Each call returns the next page of rows.
Cancels an ongoing SQL task. If no taskId is provided, cancels the current session’s active task.
Message:
{
"id": "4",
"type": "cancel",
"data": {
"sessionId": "session-123",
"taskId": "550e8400-e29b-41d4-a716-446655440000" // optional, omit to cancel the session's active task
}
}
Response:
{
"id": "4",
"retCode": 0,
"retMsg": "Task cancelled"
}
Closes the session and releases all associated resources (including any pending tasks).
Message:
{
"id": "5",
"type": "close",
"data": {
"sessionId": "session-123"
}
}
Response:
{
"id": "5",
"retCode": 0,
"retMsg": "Session closed"
}
After closing, the session ID is no longer valid.
-
Connect to WebSocket endpoint:
const WebSocket = require('ws'); const ws = new WebSocket('ws://localhost:8080/sql/ws');
-
Create a session:
ws.send(JSON.stringify({ id: "1", type: "start", data: {} }));
-
Execute a long query:
ws.send(JSON.stringify({ id: "2", type: "exec", data: { sessionId: "session-123", sql: "SELECT * FROM huge_table", maxRows: 500 } }));
-
Fetch first page:
ws.send(JSON.stringify({ id: "3", type: "fetch", data: { sessionId: "session-123", taskId: "abc123", maxRows: 100 } }));
-
Fetch subsequent pages until
hasMorebecomes false. -
Optionally cancel if needed:
ws.send(JSON.stringify({ id: "4", type: "cancel", data: { sessionId: "session-123", taskId: "abc123" } }));
-
Close the session when done:
ws.send(JSON.stringify({ id: "5", type: "close", data: { sessionId: "session-123" } }));
Note: The examples above assume you handle incoming messages asynchronously. In a real client you would match responses by their id.
The following HTTP endpoints provide basic administrative functions, such as backup, file upload/download, log viewing, and status monitoring. These endpoints are available when the Data Services API port (port_x) is enabled.
Performs a database backup. The backup file is saved in the backup/ directory with the naming pattern {database}_{backupTag}.db.
{
"backupTag": "mybackup"
}{
"retCode": 0,
"retMsg": "Successful. Backup file has placed to [C:\\Work\\slackerdb\\backup\\mydb_mybackup.db]."
}Downloads a file from the server’s working directory.
-
filename(required) – relative path to the file.
GET /download?filename=logs/slackerdb.log
The endpoint supports Range requests for partial downloads.
Uploads a file to the server’s working directory.
-
filename(required) – target file path.
-
file(required) – the file to upload.
curl -X POST -F "file=@local.txt" "http://localhost:8080/upload?filename=uploads/remote.txt""uploaded: C:\\Work\\slackerdb\\uploads\\remote.txt"Retrieves the last N lines of a log file.
-
filename(required) – path to the log file. -
lines(optional) – number of lines to return (default 100, max 10000).
GET /viewLog?filename=logs/slackerdb.log&lines=50
[
"2025-12-04 10:00:00 INFO Server started",
"2025-12-04 10:00:01 INFO Listening on port 8080"
]Returns comprehensive server status information, including server details, database metrics, configuration parameters, usage statistics, installed extensions, and active sessions.
GET /status
{
"server": {
"status": "RUNNING",
"version": "0.1.8",
"build": "2025-12-04 10:00:00.000 UTC",
"pid": 12345,
"now": "2025-12-04 15:20:00",
"bootTime": "2025-12-04 10:00:00",
"runTime": "5 hours, 20 minutes, 0 seconds"
},
"database": {
"version": "v1.0.0",
"size": "1.2 GB",
"memoryUsage": "256 MB",
"walSize": "0 B"
},
"parameters": {},
"usage": {},
"extensions": [],
"sessions": []
}
Note: The web console is not a production‑ready feature. It is a demonstration tool designed to help you understand and verify the backend services (Data Service, MCP Tool, and MCP Resource) in a visual, interactive way.
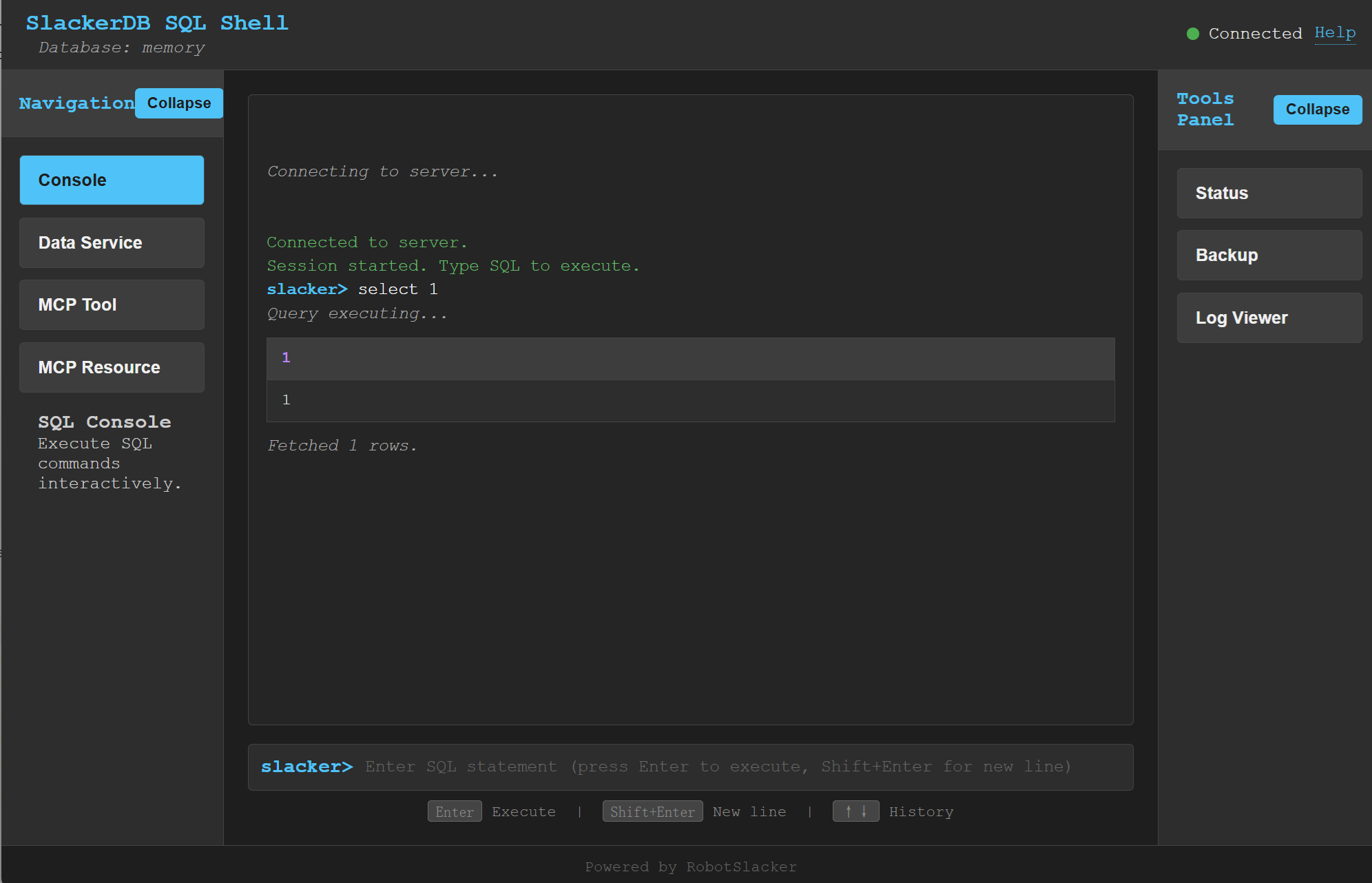
SlackerDB includes a web‑based SQL console that provides an interactive interface for executing SQL queries, viewing results, and performing administrative tasks directly from your browser. In addition to the core SQL REPL, the console offers dedicated panels for managing Data Service, MCP Tool, and MCP Resource – three key extension mechanisms of the SlackerDB ecosystem.
Access: After starting the server with the data‑service API port (port_x) enabled, open http://<server>:<port_x>/console.html in a modern browser.
Features:
-
Interactive SQL Shell: Type SQL statements at the prompt and execute them with Enter. Command history is available with up/down arrows.
-
WebSocket Connection: The console automatically connects to the SQL REPL server via WebSocket (
/sql/ws) and manages sessions. -
Tabular Results: Query results are displayed as formatted tables with column names and types.
-
Sidebar Tools Panel: Provides quick access to:
-
Server Status – detailed modal with server metrics, database parameters, usage statistics, extensions, and active sessions.
-
Backup Database – modal to create a backup with optional download of the resulting file.
-
Log Viewer – modal to inspect server logs in real time.
-
-
Connection Indicator: Visual indicator shows whether the console is connected to the server.
-
Asynchronous Execution: Long‑running queries are executed asynchronously; results can be fetched in pages.
-
Data Service Management Panel: Register, list, load, save, and unregister data services. You can also download the service definitions as a JSON file (the download will prompt you to choose a save location via the browser’s file‑picker dialog).
-
MCP Tool Management Panel: List, load, save, and unregister MCP (Model Context Protocol) tools. Download the tool definitions as JSON (with file‑picker dialog).
-
MCP Resource Management Panel: List, load, save, and unregister MCP resources. Download the resource definitions as JSON (with file‑picker dialog).
Usage:
-
Ensure the server is running with
port_xconfigured (e.g.,port_x=8080). -
Navigate to
http://localhost:8080/console.html. -
The console will attempt to connect automatically. Once connected, you can start typing SQL.
-
Use the left‑sidebar buttons to switch between the Console, Data Service, MCP Tool, and MCP Resource views.
-
In each management panel you can:
-
Refresh the list of registered items.
-
Select items with checkboxes and perform batch operations (unregister, download).
-
Load definitions from a JSON file.
-
Save definitions to the server’s configuration directory.
-
Download definitions as a JSON file – the browser will show a file‑save dialog, allowing you to choose the location and filename.
-
-
Use the right‑sidebar buttons to open status, backup, or log modals.
The console is built with plain HTML/JavaScript and requires no additional installation. It is intended for development, testing, and administrative purposes in trusted environments. Its primary goal is to demonstrate how the backend services work and to provide a convenient way to experiment with the Data Service, MCP Tool, and MCP Resource subsystems.
// create configuration, and update as your need
ServerConfiguration serverConfiguration = new ServerConfiguration();
serverConfiguration1.setPort(4309);
serverConfiguration1.setData("data1");
// init database
DBInstance dbInstance= new DBInstance(serverConfiguration1);
// startup database
dbInstance1.start();
// shutdown database
dbInstance.stop();
// We currently supports starting multiple instances running at the same time.
// But each instance must have his own port and instance name.
ServerConfiguration proxyConfiguration = new ServerConfiguration();
proxyConfiguration.setPort(dbPort);
ProxyInstance proxyInstance = new ProxyInstance(proxyConfiguration);
proxyInstance.start();
// Waiting for server ready
while (!proxyInstance.instanceState.equalsIgnoreCase("RUNNING")) {
Sleeper.sleep(1000);
}
// "db1" is your database name in your configuration file.
// 3175 is your database port in your configuration file.
// If you are connecting for the first time, there will be no other users except the default main
String connectURL = "jdbc:postgresql://127.0.0.1:3175/db1";
Connection pgConn = DriverManager.getConnection(connectURL, "main", "");
pgConn.setAutoCommit(false);
// .... Now you can execute your business logic.
// "db1" is your database name in your configuration file.
// 3175 is your database port in your configuration file.
// If you are connecting for the first time, there will be no other users except the default main
String connectURL = "jdbc:slackerdb://127.0.0.1:3175/db1";
Connection pgConn = DriverManager.getConnection(connectURL, "main", "");
pgConn.setAutoCommit(false);
// .... Now you can execute your business logic.
Since native Postgres clients often use some data dictionary information
that duckdb doesn’t have,
We do not recommend that you use the PG client to connect to this
database(That works, but has limited functionality).
Instead, we suggest use the dedicated client provided in this project.
Dbeaver:
Database -> Driver Manager -> New
Database type: generic database.
Class name: org.slackerdb.jdbc.Driver
URL template: jdbc:slackerdb://{host}:{port}/[{database}]
Based on DuckDB’s secure encryption mechanism, we support data encryption.
To use this feature, you need to:
-
Set the parameter data_encrypt to true.
-
Set the database key through any of the following three methods:
-
Environment variable: SLACKERDB_<dbName>_KEY (where <dbName> is replaced with the name of your database instance).
-
Java property: Specify it when starting the program as -DSLACKERDB_<dbName>_KEY=….
-
After startup, specify it via the statement: ALTER DATABASE <dbName> SET Encrypt Key <key>.
-
We do not support user password authentication, just for compatibility,
keep these two options.
you can fill anything as you like, it doesn’t make sense.
Only some duckdb data types are supported, mainly simple types, such as int, number, double, varchar, … For complex types, some are still under development, and some are not supported by the PG protocol, such as blob, list, map… You can refer to sanity01.java to see what we currently support.
Leave a Reply