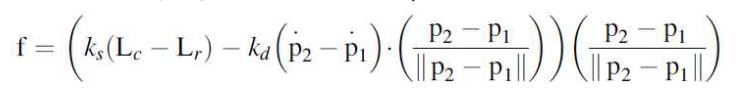ImpVec stands for immutable push vector 👿, it is a data structure which allows appending elements with a shared reference.
Specifically, it extends vector capabilities with the following two methods:
Note that both of these methods can be called with &self rather than &mut self.
Appending to a vector with a shared reference sounds unconventional, and it is.
From another perspective, however, appending an element to the end of the vector does not mutate any of already added elements or change their positions. It can be argued that it is not different than creating a new element within the scope. This statement will be clear with the following example.
The challenge is to define a type-safe, recursive and expressive expression builder. In our toy example, an expression can either be a symbol, or addition or subtraction of two expressions. The final desired ergonomic solution is as follows:
let scope = Scope::default();
// instantiate some symbols
let x = scope.symbol("x");
let y = scope.symbol("y");
assert_eq!(&x.to_string(), "x");
assert_eq!(&y.to_string(), "y");
// apply binary operations to create new symbols
let p = x + y;
assert_eq!(&p.to_string(), "x + y");
let q = x - y;
assert_eq!(&q.to_string(), "x - y");
// and further binary operations
let t = p + q;
assert_eq!(&t.to_string(), "x + y + x - y");
// we only use 'scope' to create symbols
// but in the background, all expressions are collected in our scope
let all_expressions: Vec<_> = scope.expressions.iter().map(|x| x.to_string()).collect();
assert_eq!(
all_expressions,
["x", "y", "x + y", "x - y", "x + y + x - y"]
);This at first seemed impossible in safe rust for way too many reasons. However, it is conveniently possible using an ImpVec. You may run the example in expressions.rs by cargo run --example expressions, or see the details of the implementation below.
Complete Implementation
use orx_imp_vec::*;
use std::{
fmt::Display,
ops::{Add, Sub},
};
/// A scope for expressions.
#[derive(Default)]
struct Scope<'a> {
expressions: ImpVec<Expr<'a>>,
}
impl<'a> Scope<'a> {
/// Bottom of the expressions recursion, the symbol primitive
fn symbol(&'a self, name: &'static str) -> ExprInScope<'a> {
let expr = Expr::Symbol(name);
self.expressions.imp_push(expr);
ExprInScope {
scope: self,
expr: &self.expressions[self.expressions.len() - 1],
}
}
}
/// A recursive expression with three demo variants
enum Expr<'a> {
Symbol(&'static str),
Addition(&'a Expr<'a>, &'a Expr<'a>),
Subtraction(&'a Expr<'a>, &'a Expr<'a>),
}
impl<'a> Display for Expr<'a> {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
Expr::Symbol(x) => write!(f, "{}", x),
Expr::Addition(x, y) => write!(f, "{} + {}", x, y),
Expr::Subtraction(x, y) => write!(f, "{} - {}", x, y),
}
}
}
/// Expression in a scope:
/// * it knows what it is
/// * it knows which scope it belongs to
///
/// It can implement Copy which turns out to be extremely important!
#[derive(Clone, Copy)]
struct ExprInScope<'a> {
scope: &'a Scope<'a>,
expr: &'a Expr<'a>,
}
impl<'a> ExprInScope<'a> {
/// Recall, it knows the scope it belongs to,
/// and can check it in O(1)
fn belongs_to_same_scope(&self, other: Self) -> bool {
let self_scope = self.scope as *const Scope;
let other_scope = other.scope as *const Scope;
self_scope == other_scope
}
}
impl<'a> Display for ExprInScope<'a> {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "{}", self.expr)
}
}
impl<'a> Add for ExprInScope<'a> {
type Output = ExprInScope<'a>;
/// We can create an expression by adding two expressions
///
/// Where do we store the new expression?
///
/// Of course, in the scope that both expressions belong to.
/// And we can do so by `imp_push`.
///
/// # Panics
///
/// Panics if the lhs & rhs do not belong to the same scope.
fn add(self, rhs: Self) -> Self::Output {
assert!(self.belongs_to_same_scope(rhs));
let expressions = &self.scope.expressions;
let expr = Expr::Addition(self.expr, rhs.expr);
expressions.imp_push(expr);
ExprInScope {
scope: self.scope,
expr: &expressions[expressions.len() - 1],
}
}
}
impl<'a> Sub for ExprInScope<'a> {
type Output = ExprInScope<'a>;
/// Similarly, we can create an expression by subtracting two expressions
///
/// # Panics
///
/// Panics if the lhs & rhs do not belong to the same scope.
fn sub(self, rhs: Self) -> Self::Output {
assert!(self.belongs_to_same_scope(rhs));
let expressions = &self.scope.expressions;
let expr = Expr::Subtraction(self.expr, rhs.expr);
expressions.imp_push(expr);
ExprInScope {
scope: self.scope,
expr: &expressions[expressions.len() - 1],
}
}
}
let scope = Scope::default();
// instantiate some symbols
let x = scope.symbol("x");
let y = scope.symbol("y");
assert_eq!(&x.to_string(), "x");
assert_eq!(&y.to_string(), "y");
// apply binary operations to create new symbols
let p = x + y;
assert_eq!(&p.to_string(), "x + y");
let q = x - y;
assert_eq!(&q.to_string(), "x - y");
// and further binary operations
let t = p + q;
assert_eq!(&t.to_string(), "x + y + x - y");
// we only use 'scope' to create symbols
// but in the background, all expressions are collected in our scope
let all_expressions: Vec<_> = scope.expressions.iter().map(|x| x.to_string()).collect();
assert_eq!(
all_expressions,
["x", "y", "x + y", "x - y", "x + y + x - y"]
);You may find another demonstration where an ImpVec mimics a scope in the system_of_linear_inequalities.rs example.
Finally, you may find the initial motivation of this crate and the ImpVec type in imp-vec-motivation article.
It is natural to expect that appending elements to a vector does not affect already added elements. However, this is usually not the case due to underlying memory management. For instance, std::vec::Vec may move already added elements to different memory locations to maintain the contagious layout of the vector.
PinnedVec prevents such implicit changes in memory locations. It guarantees that push and extend methods keep memory locations of already added elements intact. Therefore, it is perfectly safe to hold on to references of the vector while appending elements.
Consider the classical example that does not compile, which is often presented to highlight the safety guarantees of rust:
let mut vec = vec![0, 1, 2, 3];
let ref_to_first = &vec[0];
assert_eq!(ref_to_first, &0);
vec.push(4);
// does not compile due to the following reason: cannot borrow `vec` as mutable because it is also borrowed as immutable
// assert_eq!(ref_to_first, &0);This beloved feature of the borrow checker of rust is not required for imp_push and imp_extend_from_slice methods of ImpVec since these methods do not require a &mut self reference. Therefore, the following code compiles and runs perfectly safely.
use orx_imp_vec::*;
let mut vec = ImpVec::new();
vec.extend_from_slice(&[0, 1, 2, 3]);
let ref_to_first = &vec[0];
assert_eq!(ref_to_first, &0);
vec.imp_push(4);
assert_eq!(vec.len(), 5);
vec.imp_extend_from_slice(&[6, 7]);
assert_eq!(vec.len(), 7);
assert_eq!(ref_to_first, &0);ImpVec implements ConcurrentCollection provided that the wrapped PinnedVec is a concurrent collection (all known implementations satisfy this).
Therefore, when orx_parallel crate is included, ImpVec also automatically implements ParallelizableCollection.
This means that computations over the vector can be efficiently parallelized:
imp_vec.par()returns a parallel iterator over references to its elements, andimp_vec.into_par()consumes the vector and returns a parallel iterator of the owned elements.
You may find demonstrations in demo_parallelization and bench_parallelization examples.
Contributions are welcome! If you notice an error, have a question or think something could be improved, please open an issue or create a PR.
Dual-licensed under Apache 2.0 or MIT.
 https://github.com/orxfun/orx-imp-vec
https://github.com/orxfun/orx-imp-vec